序列标注(Sequence labeling)
BIO标注:
B — begin, I— inside, O — outside
BIO标注:将每个元素标注为“B-X”、“I-X”或者“O”。
“B-X” : 表示此元素所在的片段属于X类型并且此元素在此片段的开头
“I-X” : 表示此元素所在的片段属于X类型并且此元素在此片段的中间位置
“O” : 表示不属于任何类型。
模型:
Bi - LSTM:
选择双向LSTM的原因是,当前词的tag和前后文都有关。
具体任务:
分词:
输入:word + tag(I:in word;E:end of word)
输出:tag of word, 标签是E的后面➕空格,就达到了分词的目的
词性标注(Part-of-Speech tagging ,POS tagging):
输入:word + tag (词性:动词、名词、形容词等)
输出:词性
HMM也可以做
命名实体标注(name entity recognition, NER):
输入:word + tag(B: begin of entity,I : inside of entity, o: outside of entity)
输出:实体标注
词义角色标注 (semantic role labeling, SRL) :
输入: word + 是不是谓语(B-Argo,I-Argo,BV )
输出:语义角色
分类任务
具体任务:
文本分类
情感分类
模型:
LSTM:属于 many- to - one 的问题,最后使用 SoftMax输出分类结果。
句子关系判断
具体任务:
句法分析
蕴含关系判断(entailment)
模型:
语法分析树:
使用:LSTM 来对每个edges 算得分,选择得分高的edges,限制是这些edges 必须组成一个树
RNNGs 也可以做
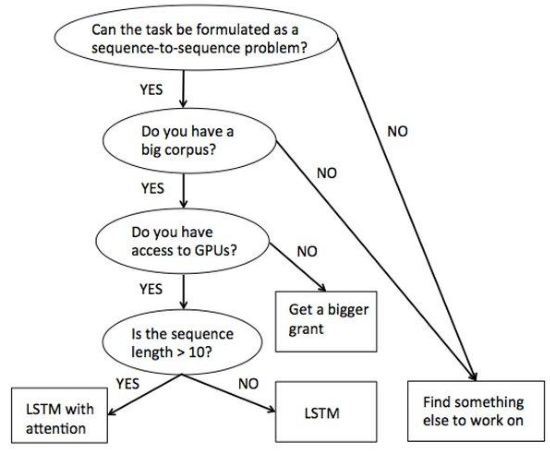
生成式任务
具体任务:
机器翻译(machine translation,MT)
Encoder-Decoder的最经典应用,事实上这一结构就是在机器翻译领域最先提出的
文本摘要、总结(summarization)
输入是一段文本序列,输出是这段文本序列的摘要序列。
阅读理解
将输入的文章和问题分别编码,再对其进行解码得到问题的答案。
语音识别
输入是语音信号序列,输出是文字序列。
对话(dialog)
输入的是一句话,输出是对这句话的回答。
Seq-2-Seq 模型:
大部分自然语言问题都可以使用 seq2seq 解决。所谓Seq2Seq(Sequence to Sequence), 就是一种能够根据给定的序列,通过特定的方法生成另一个序列的方法
Seq2Seq模型是RNN最重要的一个变种:N vs M(输入与输出序列长度不同, 这种结构又叫Encoder-Decoder模型。和RNN、LSTM 最大的区别就是这种Encoder-Decoder结构不限制输入和输出的序列长度,因此应用的范围非常广泛。